EchoProject
Video-based AI for beat-to-beat assessment of cardiac function
Introduction
This project is based on the paper “Video-based AI for beat-to-beat assessment of cardiac function,” which presents a novel deep learning algorithm, EchoNet-Dynamic, for the automated evaluation of cardiac function from echocardiogram videos.
Paper Overview
Cardiac function is crucial for maintaining normal systemic tissue perfusion. Impairment in cardiac function, often referred to as cardiomyopathy or heart failure, is a leading cause of hospitalization and a significant global health issue. One of the primary metrics for assessing cardiac function is the left ventricular ejection fraction (EF), which is critical for diagnosing cardiovascular diseases, screening for cardiotoxicity, and managing clinical decisions for patients with critical illnesses.
However, human assessment of EF involves considerable inter-observer variability and can be labor-intensive, requiring manual tracing of the ventricle size to quantify every beat. To address these challenges, the EchoNet-Dynamic algorithm leverages deep learning techniques to surpass human performance in segmenting the left ventricle, estimating EF, and assessing cardiomyopathy.
EchoNet-Dynamic Algorithm
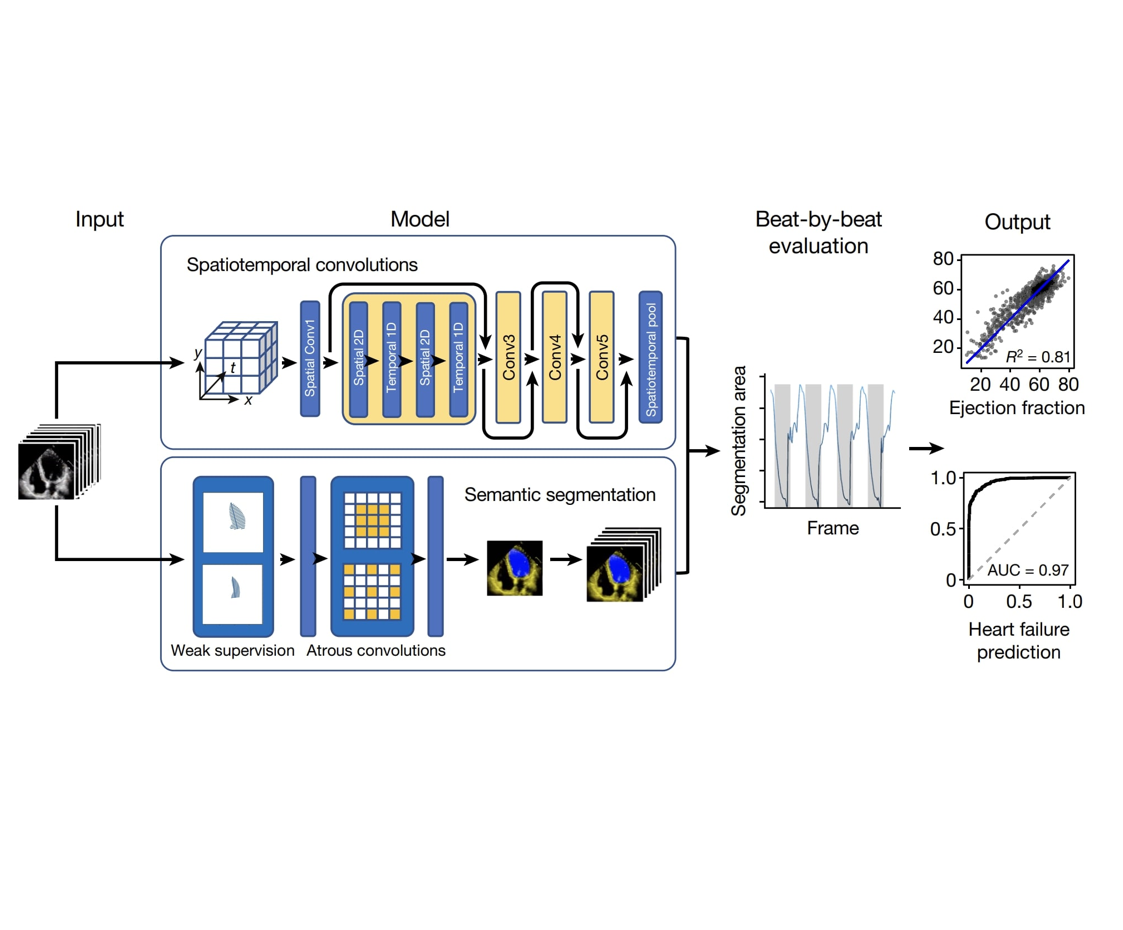
EchoNet-Dynamic consists of three key components:
- Frame-Level Semantic Segmentation:
- Utilizes a convolutional neural network (CNN) with atrous convolutions for frame-level segmentation of the left ventricle.
- This approach captures larger patterns and generates segmentation throughout the cardiac cycle, providing an interpretable intermediary that mimics the clinical workflow.
- Spatiotemporal Convolutions for EF Prediction:
- A CNN model with residual connections and spatiotemporal convolutions predicts EF from the echocardiogram videos.
- This architecture integrates both spatial and temporal information, enhancing the model’s ability to capture patterns across frames.
- Beat-to-Beat Estimation of Cardiac Function:
- The model identifies each cardiac cycle and generates a clip of 32 frames, averaging clip-level EF estimates for each beat.
- This approach reduces the error in EF estimation by leveraging information across multiple cardiac cycles, allowing for precise diagnosis of cardiovascular diseases in real-time.
Model Performance
EchoNet-Dynamic was trained on a dataset of 10,030 echocardiogram videos obtained from routine clinical practice at Stanford Medicine. The model’s performance was evaluated on an unseen test dataset, achieving a mean absolute error of 4.1%, root mean squared error of 5.3%, and R² of 0.81 compared to human annotations. These results demonstrate that EchoNet-Dynamic’s variance is comparable to or less than that of human experts.
In addition to its robust performance on the Stanford test dataset, EchoNet-Dynamic was tested on an external dataset from Cedars-Sinai Medical Center, achieving a mean absolute error of 6.0%, root mean squared error of 7.7%, and R² of 0.77. This cross-hospital reliability highlights the model’s potential for broader clinical application.
Dataset Availability
To promote further innovation, the authors have made publicly available a large dataset of 10,030 annotated echocardiogram videos. This dataset includes expert human tracings, volume estimates, and calculations of the left ventricular EF, providing a valuable resource for the medical machine learning community.
Project Implementation
In this project, I reproduced the EF prediction model and the segmentation model from EchoNet-Dynamic. I finetuned the EF prediction model on our dataset. Due to data imbalance, I manually collected more rare data to improve model performance.
A4C EF Results
Without segmentation:
test (one clip) R2: 0.937 (0.889 - 0.962)
test (one clip) MAE: 2.66 (2.18 - 3.19)
test (one clip) RMSE: 3.38 (2.74 - 4.02)
test (all clips) R2: 0.927 (0.882 - 0.952)
test (all clips) MAE: 2.83 (2.28 - 3.39)
test (all clips) RMSE: 3.63 (3.01 - 4.21)

With segmentation:
(To reproduce, use the for_R directory and run the R script.)
> summary(abs(dataNoAugmentation$V3 - dataNoAugmentation$EF))
Min. 1st Qu. Median Mean 3rd Qu. Max.
0.0546 0.9325 2.4867 2.8639 4.2843 10.2367
> rmse(dataNoAugmentation$V3,dataNoAugmentation$EF)
[1] 3.6722
> summary(modelNoAugmentation)$r.squared
[1] 0.9285011
Paper Result:
summary(abs(dataNoAugmentation$V3 - dataNoAugmentation$EF))
# Mean of 4.216
rmse(dataNoAugmentation$V3,dataNoAugmentation$EF)
## 5.56
summary(modelNoAugmentation)$r.squared
# 0.79475
Our model outperforms the paper’s results for the A4C EF task without segmentation.
A2C EF Results
Without segmentation:
test (one clip) R2: 0.934 (0.908 - 0.958)
test (one clip) MAE: 2.75 (2.04 - 3.54)
test (one clip) RMSE: 3.73 (2.54 - 4.91)
test (all clips) R2: 0.931 (0.906 - 0.954)
test (all clips) MAE: 2.85 (2.14 - 3.67)
test (all clips) RMSE: 3.81 (2.71 - 4.89)

With segmentation:
> summary(abs(dataNoAugmentation$V3 - dataNoAugmentation$EF))
Min. 1st Qu. Median Mean 3rd Qu. Max.
0.0392 1.2950 2.4707 3.0739 4.4038 13.9361
> rmse(dataNoAugmentation$V3,dataNoAugmentation$EF)
[1] 4.074103
> summary(modelNoAugmentation)$r.squared
[1] 0.9306509
Paper Result:
summary(abs(dataNoAugmentation$V3 - dataNoAugmentation$EF))
# Mean of 4.216
rmse(dataNoAugmentation$V3,dataNoAugmentation$EF)
## 5.56
summary(modelNoAugmentation)$r.squared
# 0.79475
Our model outperforms the paper’s results for the A2C EF task without segmentation.
Trails
I conducted 9-fold cross-validation, with R² variations within ±0.04. Hyperparameter tuning showed that unfreezing 3 layers performed best.
LAV
I focused on videos with a lower chamber view and used several data augmentation techniques. The best method was training from the last best point.
Data
Three folders contain almost all data (excluding echonet videos):

Old videos are in EchoNet-A2C/crop_clear_old and EchoNet-A4C/crop_clear_old, while new EF videos and old videos are in EchoNet-A2C/crop_clear_all and EchoNet-A4C/crop_clear_all.
Echonet dataset: Echonet Dataset
Fine Tuning
Refer to this paper for fine-tuning models.
LAV A2C Result:
test (one clip) R2: 0.784 (0.354 - 0.923)
test (one clip) MAE: 7.88 (5.18 - 11.01)
test (one clip) RMSE: 10.24 (6.68 - 13.61)
test (all clips) R2: 0.785 (0.326 - 0.923)
test (all clips) MAE: 8.10 (5.51 - 10.96)
test (all clips) RMSE: 10.24 (6.86 - 13.51)

LAV A4C Result:
test (one clip) R2: 0.818 (0.632 - 0.901)
test (one clip) MAE: 6.27 (4.46 - 8.19)
test (one clip) RMSE: 8.34 (6.34 - 10.11)
test (all clips) R2: 0.710 (0.331 - 0.915)
test (all clips) MAE: 6.71 (4.29 - 9.74)
test (all clips) RMSE: 10.55 (5.74 - 15.24)
